每周花时间阅读技术文章,摘录精华
花1小时写代码,就要花10小时检查代码。查找漏洞都成了写代码的一部分了,这个差距太悬殊。就算写代码多费点时间,代码也要简单易懂。
—— Robert C. Martin《Clean Code: A Handbook of Agile Software Craftsmanship》
高性能开源通用RPC框架,谷歌出品
以前用RPC开发过一个分布式系统,那么gRPC又是什么?
与许多 RPC 系统类似,gRPC 也是基于以下理念:定义一个服务,指定其能够被远程调用的方法(包含参数和返回类型)。在服务端实现这个接口,并运行一个 gRPC 服务器来处理客户端调用。在客户端拥有一个存根能够像服务端一样的方法。
高并发系统HTTP缓存
- 服务端响应的Last-Modified会在下次请求时以If-Modified-Since请求头带到服务端进行文档是否修改的验证,如果没有修改则返回304,浏览器可以直接使用缓存内容;
- Cache-Control:max-age和Expires用于决定浏览器端内容缓存多久,即多久过期,过期后则删除缓存重新从服务端获取最新的;另外可以用于from cache场景;
- http/1.1规范定义的Cache-Control优先级高于http/1.0规范定义的Expires;
- 一般情况下Expires=当前系统时间+缓存时间(Cache-Control:max-age);
- http/1.1规范定义了ETag来通过文档摘要的方式控制。
携程大数据实践:高并发应用架构及推荐系统案例
有比较大的参考价值,当然整体架构都描述的比较笼统.
应用系统的整体架构
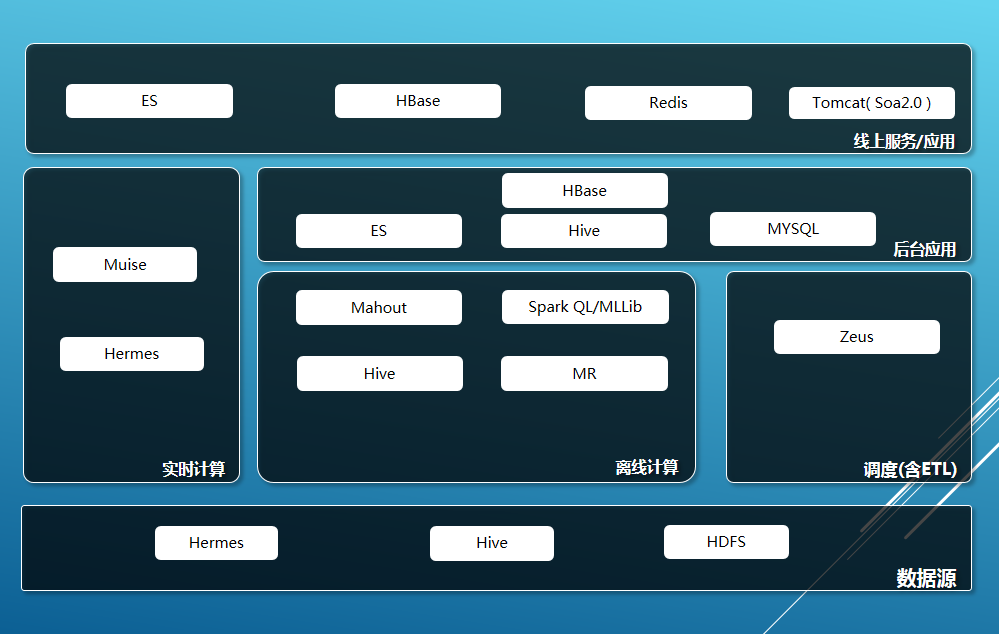
数据源部分,Hermes是携程框架部门提供的消息队列,基于Kafka和MySQL做为底层实现的封装,应用于系统间实时数据传输交互通道。Hive和HDFS是携程海量数据的主要存储,两者来自Hadoop生态体系。
离线部分,包含的模块有MR、Hive、Mahout、SparkQL/MLLib。Mahout提供基于Hadoop平台进行数据挖掘的一些机器学习的算法包。Spark类似hadoop也是提供大数据并行批量处理平台,但是它是基于内存的。SparkQL 和Spark MLLib是基于Spark平台的SQL查询引擎和数据挖掘相关算法框架。携程主要用Mahout和Spark MLLib进行数据挖掘工作。
调度系统zeus,是淘宝开源大数据平台调度系统.
近线部分,是基于Muise来实现我们的近实时的计算场景,Muise是也是携程OPS提供的实时计算流处理平台,内部是基于Storm实现与HERMES消息队列搭配起来使用。例如,我们使用MUSIE通过消费来自消息队列里的用户实时行为,订单记录,结合画像等一起基础数据,经一系列复杂的规则和算法,实时的识别出用户的行程意图。
后台/线上应用部分,MySQL用于支撑后台系统的数据库。ElasticSearch是基于Lucene实现的分布式搜索引擎,用于索引用户画像的数据,支持离线精准营销的用户筛选,同时支持线上应用推荐系统的选品功能。HBase 基于Hadoop的HDFS 上的列存储NoSQL数据库,用于后台报表可视化系统和线上服务的数据存储。
这里说明一下, 在线和后台应用使用的ElasticSearch和HBase集群是分开的,互不影响。Redis支持在线服务的高速缓存,用于缓存统计分析出来的热点数据。
系统案例
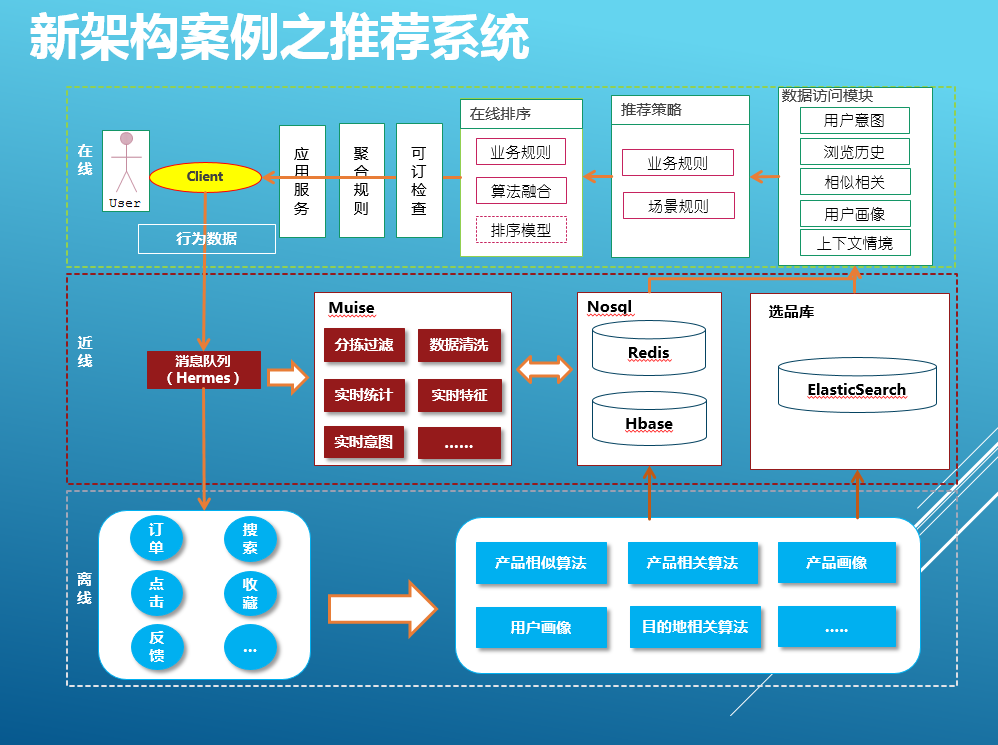
- 数据源,分结构化数据和非结构化数据.
- 离线计算,经过数据预处理,数据挖掘,和数据配置后(建立ES索引),输出产品画像,用户画像等.
- 近线计算,输出用户意图和产品缓存.
大数据4V特征
大数据的特点,按照IBM提出的,4V特性:
- Volume(海量): 数量大
- Velocity(速度): 数据量增长快
- Variety(多样性): 各种各样类型的数据出现
- Varacity(准确性): 数据的准确性
日志分析智能化
日志是企业内部宝贵的IT大数据,相比excel和数据库而言,日志是非结构化数据,需要进行进一步的挖掘.
日志易的技术架构: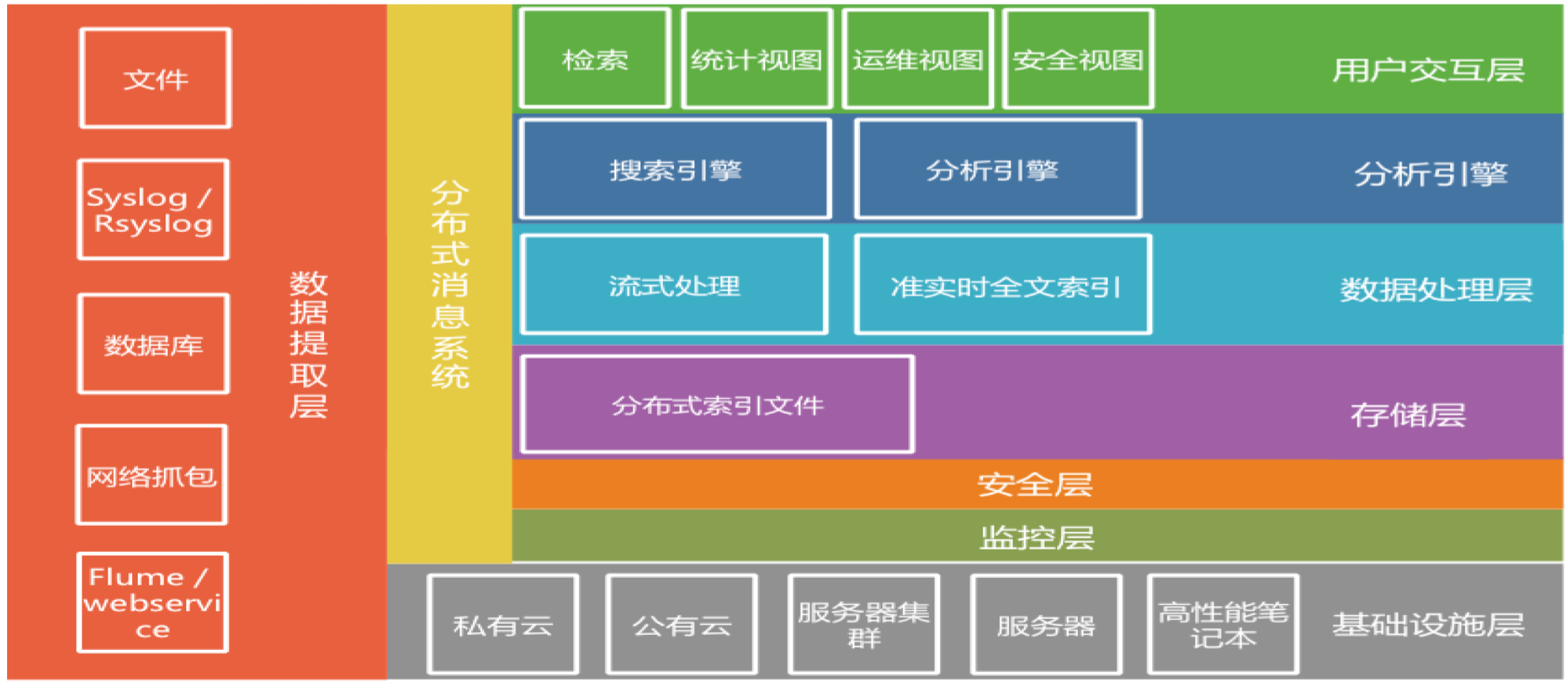
实现了搜索处理语言SPL(Search Processing Language),用户可以在搜索框里编写SPL脚本,对日志进行复杂的关联分析,非常强大、灵活,实现了“框计算”
IOS动态更新方案
JSPatch 是 iOS 平台上的一个开源库,只需接入极小的三个引擎文件,即可以用 JavaScript 调用和替换任意 Objective-C 方法,也就是说可以在 App 上线后通过下发 JavaScript 脚本,实时修改任意 Objective-C 方法的实现,达到修复 Bug 或动态运营的目的。
如果作为热更新工具,相比RN,更轻量级,更稳定些,学习成本也稍低些.
人工智能的挑战
人工智能技术前景?
- 无监督预测学习,例如联想能力;
- 单例(有限例)学习;
- 结合贝叶斯统计的深度学习,使得融入由因到果或互为因果的relation变得容易;
- 层级增强的memory,reasoning,planning的表征方法;
- 深度增强学习;
- 动态neural turing machine及其变种。
这些技术的落地应用,可以使得相当程度的机器智能改善人类生活,例如机器助理,自动驾驶,智能服务等.
技术人员需要学习那些人工智能技术?
- 人工智能未来应该是一种工具,会用就好,软件工程师需要考虑如何将人工智能的工具应用到实际产品中.
- 人工智能是一种思维方式,工程师重新审视自己的工作方式:是否可以借鉴AI来改善和提升现在的工作?
移动端高效实用SQLite
移动端少量的KV类型数据库可以直接存在文件上,稍微复杂一点的格式化成JSON或XML保存.在更大的量级上则需要使用SQLite.
数据库初始化
设置合理的page_size和cache_size
SQLite 数据库把其所存储的数据以 page 为最小单位进行存储。cache_size 的含义为当进行查询操作时,用多少个 page 来缓存查询结果.
可能影响到 page_size 和 cache_size 最优值选取的三个因素:
- table_size
- 存储的数据类型
- 增删查改比例
通过timer控制数据库事务定时提交
一个Transaction能够大大的提升其内部的增删改查操作的速度.事务的引入能提升性能两个数量级以上.
数据库完整性校验
移动客户端的数据库运行环境比较复杂,需呀校验数据库的完整性,
1 | PRAGMA integrity_check |
如执行失败就需要回滚到上一个版本.
数据库升级逻辑
可以在meta表中并加入版本号,SQL语句需通过版本号来提供兼容性.
1 | CREATE TABLE meta (key LONGVARCHAR NOT NULL UNIQUE PRIMARY KEY, value LONGVARCHAR) |
高效SQL语句
- 建立索引,就是将这列以及主键所有数据取出。以索引列为主键按照升序,原表主键为第二列,重新创建一张新的表。使其搜索速度降低到 Log(N)。
- 先SELECT 再选择 INSERT OR UPDATE 的方法。
- FTS(Full Text Search)是SQLite未加快字符串搜索而创建的虚拟表.通过分词大大加快英文类/中文类字符串(配合ICU)的搜索速度.
- 为做到数据库Model跨IOS,Android平台,用protobuf作为数据库的输入输出参数.两个平台用一份proto文件分别生成各自的实现文件.
- 不是用SQLite的多线程实现,多线程会增加线程开销而且操作加锁,性能比较差.
- 加密数据库.加密对性能损耗大约是3%的CPU时间.
移动端开发流程
- web端流程. 产品经理提出需求(原型等)>讨论需求>通过需求>交付设计师设计layout>确认>切页面>交付工程师开发>后端(前端)定接口>前后端并行开发>修改细节及bug>上线。
- 移动客户端. 产品经理提出需求(原型等)>讨论需求>通过需求>设计layout(包括交互设计及ui设计)>确认>切图>交付工程师开发>后端接口开发/移动开发>上线。
大体上的流程都不会变,移动端的如果使用Native开发,那前端就消失了,切图部分交给UI来做.
移动端的产品设计交互性和逻辑性会更强,所以原型设计需要由设计把控交互部分,如果产品经理无法把控交互部分,至少要画出概念图和流程图,交给设计师进行设计.
移动设计相比web端设计有一些异同点:
- 字体选用. web端一般是宋体或者微软雅黑. IOS:冬青黑体或者华文黑体. Android: Droid Sans Fallback, 冬青黑或者华文黑也可以考虑.
- 简单易用.
- 分辨率. iphone + andorid存在大量的分辨率,需要设计适配.
- 切图.
- 安卓和iphone差别交互设计.
架构设计主要是后端,需要考虑如何提供高性能的API接口,接口的制定可以由后端牵头也可以由移动开发人员牵头.
运营产品核心指标分析流程
电商产品
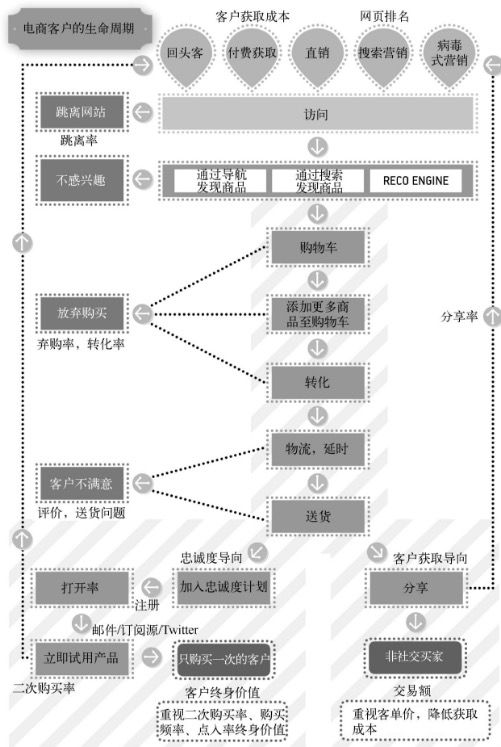
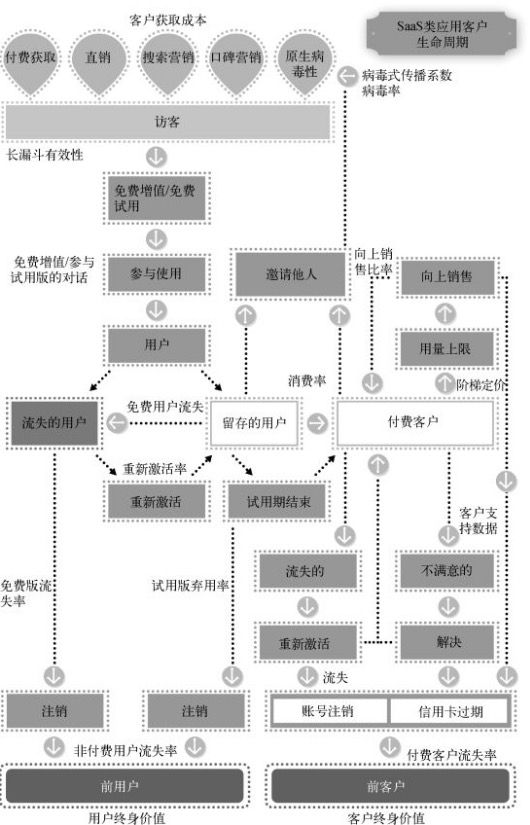
SaaS类产品和移动用户产品的核心指标
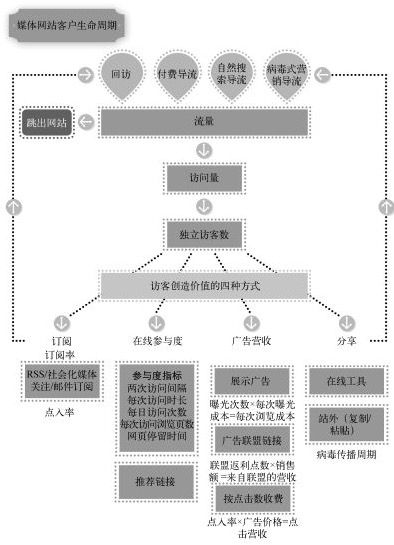
内容网站关注的核心指标
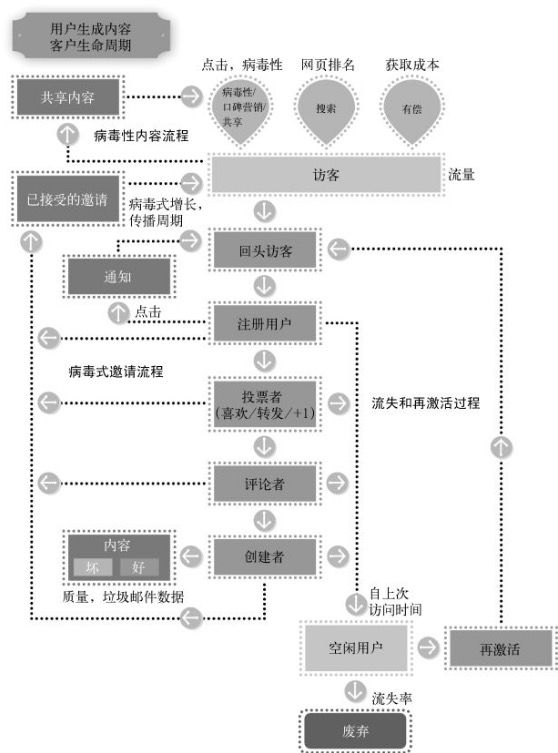
UGC,社交站关注的核心指标
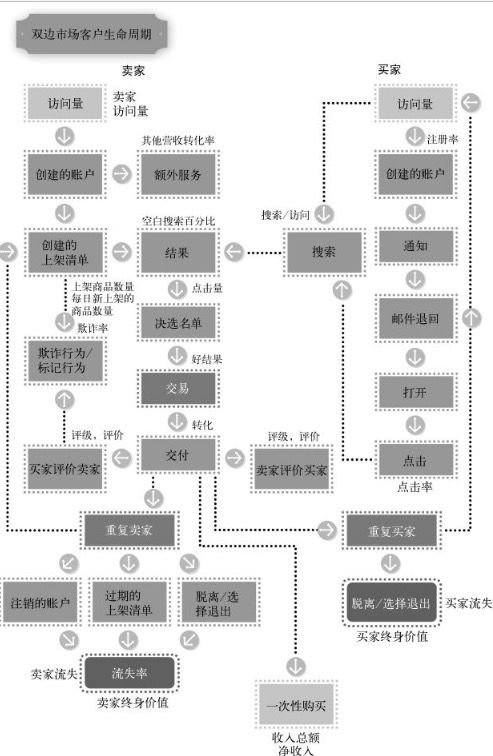
双边市场(服务方与提供服务方)关注的指标