什么是hadoop?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不知道底层细节的情况下,将可自己的程序运行在分布式系统上,利用计算机集群对海量数据进行高速的数据运算和存储.
要学习hadoop,首先要了解它的核心设计:MapReduce和HDFS.
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),是一个具备高度容错性的文件系统,可以部署在廉价的系统上.
基本架构
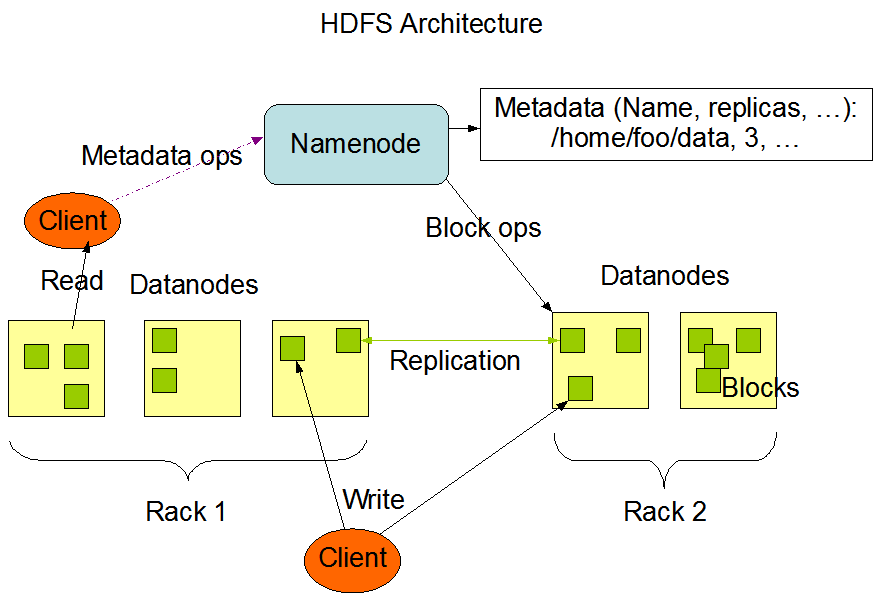
Block: 块文件,通常是64M.DataNode:用于存储Block块文件.NameNode: 保存整个文件系统的目录,文件和分布信息.指示文件是如何被拆分成block以及这些block都存储到了哪些DateNode节点上.通常只有一台,2.X版本提供了master-slave模式.
MapReduce
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算.基本原理就是:分析大数据,然后析分成小块逐个分析,最后再将提取出来的数据汇总分析,最终获得我们想要的内容。
MapReduce操作的都是
(input)
-> map -> -> combine -> -> reduce -> (output)
Apache hadoop家族
基础成员
- Hadoop Common
- Hadoop Distributed File System (HDFS™)
- Hadoop MapReduce
其他成员
- Hadoop YARN: 用于工作调度和集群资源管理的框架.
- Avro™: 是一个数据序列化系统,设计用于支持数据密集型,大批量数据交换的应用.Avro是新的数据序列化格式与传输工具,将逐步取代Hadoop原有的IPC机制.
- Cassandra™:是一套开源分布式NoSQL数据库系统.
- Chukwa™: 是一个开源的用于监控大型分布式系统的数据收集系统,它可以将各种各样类型的数据收集成适合Hadoop处理的文件,并保存在HDFS中供Hadoop进行各种MapReduce操作.
- HBase™: 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群.
- Hive™: 基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析.
- Mahout™: 基于Hadoop的机器学习和数据挖掘的一个分布式框架.Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
- Pig™: Pig提供更高级的数据流语言,类似SQL的语言(Pig Latin),有效提高MapReduce编写的抽象表现能力.
- Spark™: 一个新兴的大数据处理引擎,提供了一个集群的分布式抽象模型RDD(Resilient Distributed Dataset).支持的实际应用范围非常广,如:ETL,机器学习,图像处理等.
- Tez™: 是Apache最新开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output,Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业.
- ZooKeeper™: 是一个为分布式应用所设计的分布的、开源的协调服务,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,简化分布式应用协调及其管理的难度,提供高性能的分布式服务.
环境准备
docker run -it invain/hadoop
hadoop案例:统计词频
统计一个文本文件,一本书,或者一个web上各个单词出现的频率.
WordCount.java源码
1 | import java.io.IOException; |
编译
1 | hadoop com.sun.tools.javac.Main WordCount.java |
创建FS
在hdfs上的用户目录下创建输入/输出文件的文件夹.
hadoop fs -mkdir -p /user/{whoami}/wordcount/input
下本书
1 | mkdir -p ~/tmp/book/ |
将书放到HDFS上
hadoop fs -put ~/tmp/book/*.txt /user/${whoami}/input
运行程序
1 | hadoop jar wc.jar WordCount /user/${whoami}/wordcount/input /user/${whoami}/wordcount/output |
查看解析内容hadoop fs -cat /user/${whoami}/wordcount/output/part-r-00000
hadoop steaming
Hadoop是使用Java语言编写的,所以最直接的方式的就是使用Java语言来实现Mapper和Reducer,然后配置MapReduce Job,提交到集群计算环境来完成计算.
hadoop也为其它语言,如C++、Shell、Python、 Ruby、PHP、Perl等提供了支持,这个工具就是Hadoop Streaming.
wordcount的python实现
mapper.py源码
1 | #!/usr/bin/env python |
reducer.py
1 | #!/usr/bin/env python |
运行
可以写个sh脚本运行
1 | hadoop jar $STREAM \ |