Docker形式的Hadoop
Hadoop环境搭建
创建hadoop用户
增加hadoop用户,授予管理员权限,并登录
1 | $ sudo useradd -m hadoop |
安装配置SSH
1 | $ sudo apt-get install openssh-server |
设置免密码登录,生成私钥和公钥,并将公钥追加到 authorized_keys中,它为用户保存所有允许登录到ssh客户端用户的公钥内容。
1 | $ ssh-keygen -t rsa -P "" |
在SSH安装之后,对SSH进行测试$ssh localhost
安装Hadhoop
安装Java环境
sudo apt-get install openjdk-7-jdk
配置 JAVA_HOME, 获取java安装目录
1 | hadoop@78dd25fb63f7:/usr/local/hadoop$ update-alternatives --config java |
配置环境变量$ emacs ~/.bashrc并export JAVA_HOME=JDK安装路径
1 | $ source ~/.bashrc |
安装Hadoop2.7
1 | wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz |
添加以下环境变量:
1 | #HADOOP VARIABLES START |
查看Hadhoop版本,验证是否成功
1 | hadoop version |
运行测试程序
步骤 1
创建一个临时的Input目录,将需要处理的文件copy到input文件夹下。
1 | $ mkdir input |
步骤 2
利用Hadoop进行单词计数处理,统计input文件夹中所有文件中含有单词的次数
1 | hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount input output |
查看
1 | hadoop@VM-160-8-ubuntu:~$ cat output/* |
Hadoop伪分布式安装
core-site.xml
core-site.xml文件中包含Hadoop实例的端口号信息, 文件系统的内存分配信息,存储数据的内存限制,读/写缓冲区的容量等信息。 打开core-site.xml文件,并在, 标签之间添加以下属性信息。
cd $HADOOP_HOME/etc/hadoop
1 | <configuration> |
hdfs-site.xml
hdfs-site.xml文件包括本地文件系统中复制数据,主节点路径,数据节点路径等信息,该文件主要储存Hadoop基础设施。
1 | <configuration> |
yarn-site.xml
在以上文件中,所有的属性值都是用户定义的,可以通过改变属性值Hadoop基础构架,yarn-site.xml能够配置Hadoop的yarn,打开yarn-site.xml文件,在, 标签之间添加属性。
1 | <configuration> |
mapred-site.xml
mapred-site.xml文件说明哪一个MapReduce框架正在被使用。在默认状态下,Hadoop包含一个yarn-site.xml模板。 首先,需要使用cp命令复制mapred-site,xml.template到mapred-site.xml文件。
1 | $ cp mapred-site.xml.template mapred-site.xml |
打开mapred-site.xml文件,并在, 标签之间添加属性。
1 | <configuration> |
Hadoop启动
建立主节点
建立主节点使用hdfs namenode -format命令。
1 | $ cd ~ |
命令正确执行后,可以得到以下的输出结果。
1 | hadoop@VM-160-8-ubuntu:/usr/local/hadoop/etc/hadoop$ hdfs namenode -format |
启动Hadoop的dfs文件系统
以下命令用来启动dfs,启动Hadoop文件系统。(2.7需将 /etc/hadoop/hadoop-env.sh中的 JAVA_HOME设为绝对路径)
1 | export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 |
1 | hadoop@VM-160-8-ubuntu:~$ start-dfs.sh |
启动Yarn脚本
以下命令启动yarn script,执行这个命令将会启动yarn daemons程序。
1 | $ start-yarn.sh |
通过浏览器访问Hadoop
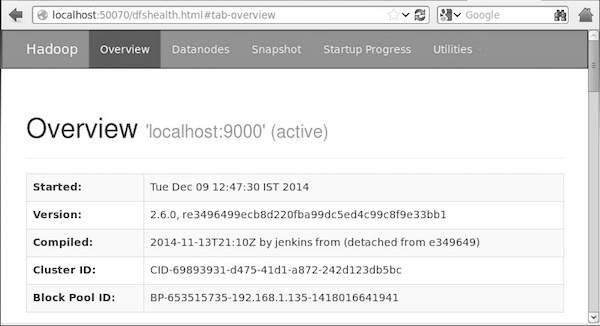
Hadoop默认的端口号是50070,使用以下命令访问Hadoop服务。http://localhost:50070/
图1-Hadoop服务
启动集群中所有的应用程序
默认的端口号8088能够访问所有的应用程序,使用以下url能够访问这个服务。http://localhost:8088/
图2-Hadoop应用程序
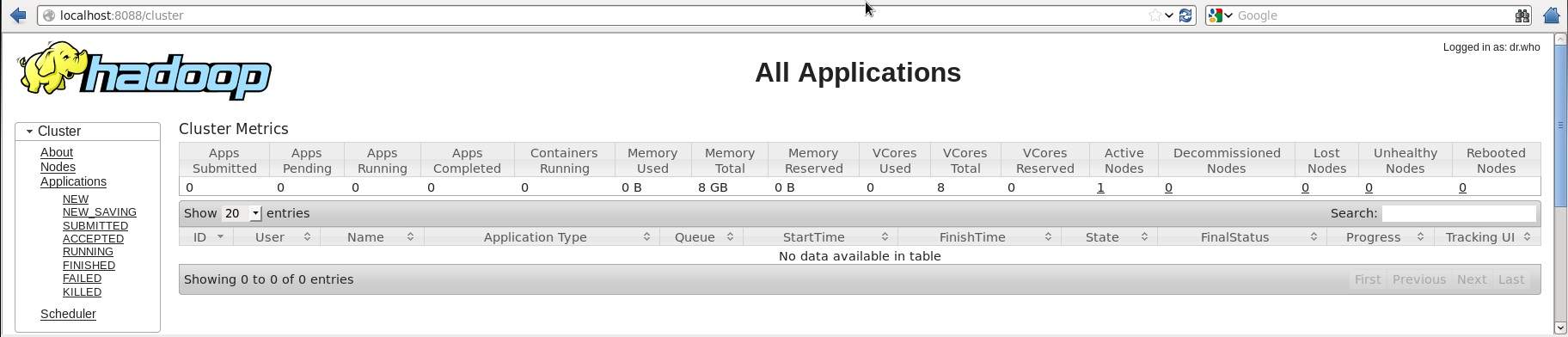
出现以上图片表明Hadoop程序已经完成部署。
Spark安装
获取并解压到Hadoop中.
1 | wget https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz |
配置环境变量:
1 | export SPARK_HOME=$HADOOP_HOME/spark2 |
进入Spark安装路径,配置spark环境变量:cp spark-env.sh.template spark-env.sh
加入如下环境变量
1 | export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 |
sbin/start-all.sh启动spark, 8080端口访问spark的web站点