Sql
定义
SQL是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
特点:
- 是一种高级的非过程化编程语言,允许用户在高层数据结构上工作。
- 它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式。
- 结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。
组成
SQL由六个部分组成:
- 数据查询语言(DQL)
- 数据操作语言(DML)
- 事务处理语言(TPL)
- 数据控制语言(DCL)
- 数据定义语言(DDL)
- 针控制语言(CCL)
RMDB
定义
RDBMS(关系型数据库): R, 即 “Relational” (有关系,关联的),是其中内容最丰富的部分. 数据通过 表 (table) 进行组织,每张表都是一些由 类型 (type) 相关联的 列 (column) 构成. 所有表,列及其类的类型被称为数据库的 schema (架构或模式).
schema 通过每张表的描述信息完整刻画了数据库的结构.
比如, 一张叫做 Car 的表可能有以下一些列:
1 | Make: a string |
在一张表中,每个单一的条目叫做一行(row)或者一条记录(record).
为了区分每条记录, 通常会定义一个 主键 (primary key).
表中的主键是其中一列, 它能够唯一标识每一行.
在表 Car 中, VIN 是一个天然的主键选择, 因为它能够保证每辆车具有唯一的标识.
Schemas
schema , 描述了列的名字及其所包含数据的类型。它还包括了其他一些信息, 比如哪些列可以为空, 哪些列不允许有重复值, 以及其他对表中列的所有限制信息。 在任意时刻一张表只能有一个 schema, 并且 表中的所有行必须遵守 schema 的规定 。
如果在传统的关系型数据库中,因为业务的需求需要新增一些字段,就需要变更表-添加新的列,对一个大型数据库做一些改变通常并不是一件小事。DBA需要做大量的schema维护工作。
Querying
SQL 能够让我们通过对数据库进行query (查询)来获取有用的信息.
查询简单来说, 查询就是用一个结构化语言向 RDBMS 提问,返回的行就是问题的答案.
我们可以通过在数据库上进行如下的 SQL 查询 :
1 | SELECT Make, Model FROM Car; |
将SQL大致翻译成中文:
向我展示(SELECT)表 Car(FROM) 每一行中 Make 和 Model 的值.
查询特定的表,使用表的主键VIN来标示唯一的一辆车:
1 | SELECT * FROM Car WHERE VIN = '2134AFGER245267' |
Relations
数据库设计三大范式:
- 第一范式:确保每列的原子性.
- 第二范式:确保表中的每列都和主键相关.
- 确保每列都和主键列直接相关,而不是间接相关.
ServiceHistory 表:
1 | VIN | Make | Model | Year | Color | Service Performed | Mechanic | Price | Date |
->Vehicle+ServiceHistory表
1 | VIN | Make | Model | Year | Color |
1 | VIN | Service Performed | Mechanic | Price | Date |
对两表做关联查询,如果数据库没有建立索引(indices),上面的查询就需要进行表扫描(table scan).
NOSQL
NOSQL数据库分类
分类 Examples举例 典型应用场景 数据模型 优点 缺点
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值 | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | centered | $12 |
| 文档型数据库 | CouchDB, MongoDb,SequoiaDB | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案。 |
RMDB vs NOSQL-DB
关系型数据库
优点
- 事务处理—保持数据的一致性;
- 由于以标准化为前提,数据更新的开销很小(相同的字段基本上只有一处);
- 可以进行Join等复杂查询
缺点:
- 扩展困难:由于存在类似Join这样多表查询机制,使得数据库在扩展方面很艰难;
- 读写慢:这种情况主要发生在数据量达到一定规模时由于关系型数据库的系统逻辑非常复杂,使得 其 非常容易发生死锁等的并发问题,所以导致其读写速度下滑非常严重;
- 成本高:企业级数据库的License价格很惊人,并且随着系统的规模,而不断上升;
- 有限的支撑容量:现有关系型解决方案还无法支撑Google这样海量的数据存储;
非关系型数据库
优点:
- 简单的扩展:比如Cassandra的架构类似于P2P,所以能通过轻松地添加新的节点来扩展这个集群;
- 快速的读写:比如Redis,由于其逻辑简单,且支持内存,使得其性能非常出色,单节点每秒可以处理超过10万次读写操作;
- 低廉的成本:这是大多数分布式数据库共有的特点,因为主要都是开源软件,没有昂贵的License成本;
缺点:
- 不提供对SQL的支持:如果不支持SQL这样的工业标准,将会对用户产生一定的学习和应用迁移成本;
- 支持的特性不够丰富:现有产品所提供的功能都比较有限,大多数NoSQL数据库都不支持事务,也不像MS SQL和Oracle那样能提供各种附加功能,比如BI和报表等;
- 现有产品的不够成熟:大多数产品都还处于初创期,和关系型数据库几十年的完善不可同日而语;
主流数据库
![]()
ORM
定义
orm英文全称object relational mapping,就是对象映射关系程序,简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,而不用直接使用sql语言。
优点:
ORM的核心:隐藏了数据访问细节。它使得我们的通用数据库交互变得简单易行,不用熟悉SQL语句以及数据库的异构性。ORM使我们构造固化数据结构变得简单易行。
缺点:
无可避免的,自动化意味着映射和关联管理,代价是牺牲性能。现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
Python ORM库
SQAlchemy
安装
1 | pip install SQAlchemy |
架构
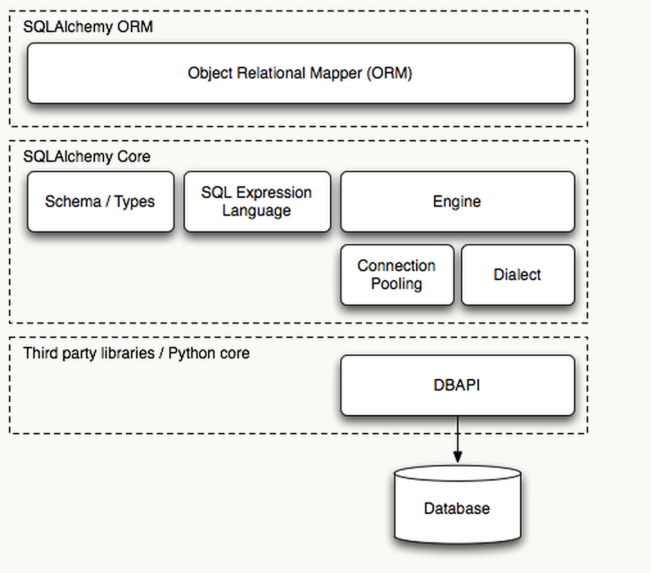
示例代码
1 | from sqlalchemy import Column, DateTime, String, Integer, ForeignKey, func |
练习:写一个轻量级的数据库
设计思路:
- 一个 Python 的 dict 作为主要的数据存储
- 仅支持 string 类型作为键 (key)
- 支持存储 integer, string 和 list
- 简单 TCP/IP 服务器用来传递消息
- 一些像 INCREMENT, DELETE , APPEND 和 STATS 这样的高级命令
所需支持的命令行
1 | PUT |
消息结构
请求消息
一条 请求消息 (Request Message) 包含了一个命令(command),一个键 (key), 一个值 (value), 一个值的类型(type). 后三个取决于消息类型,是可选项, 非必须。; 被用作是分隔符。即使并没有包含上述可选项, 但是在消息中仍然必须有三个 ; 字符。
1 |
|
COMMAND是上面列表中的命令之一KEY是一个可以用作数据库 key 的 string (可选)VALUE是数据库中的一个 integer, list 或 string (可选)list可以被表示为一个用逗号分隔的一串 string, 比如说, “red, green, blue”VALUE TYPE描述了 VALUE 应该被解释为什么类型- 可能的类型值有:INT, STRING, LIST
示例
1 | "PUT; foo; 1; INT" |
响应消息
一个 响应消息 (Reponse Message) 包含了两个部分, 通过 ; 进行分隔。第一个部分总是 True|False , 它取决于所执行的命令是否成功。 第二个部分是命令消息 (command message),当出现错误时,便会显示错误信息。对于那些执行成功的命令,如果我们不想要默认的返回值(比如 PUT), 就会出现成功的信息。 如果我们返回成功命令的值 (比如 GET), 那么第二个部分就会是自身值。
Examples
1 | True; Key [foo] set to [1] |
示例代码
1 | # coding : utf-8 |