爬虫入门简单,精通也不易。虽然爬虫是Python的看家本领,网上也有大量的教程,但是大部分文章所涉及的内容都的粗浅,没有系统性的介绍,也不具备工程实战性。遂系统性的梳理一下。
什么是爬虫
爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
如果把互联网比喻成一个蜘蛛网,Spider就是一只在网上爬来爬去的蜘蛛。网络爬虫就是根据网页的地址来寻找网页的,也就是URL。Google、baidu就是最大的爬虫,搜索引擎的数据内容都是由网络蜘蛛爬去网络而来。
什么是URL
URL:统一资源定位符(Uniform Resource Locator),一般格式如下:
protocol ://hostname[port]/path/[parameters][?query]#fragment
URL的格式由三部分组成:
- protocol:协议,通讯协议。一般使用TCP/IP应用层协议,例如http/https/ftp/smb等等;
- hostname[:port]:主机名[端口号];
- path: 资源在主机中的具体地址,如目录和文件名等。
通常,爬虫使用URL来获取(Request)资源信息,并对返回内容(Response)做对应的解析和处理。返回的内容比较多样,比如文本、图片、excel/csv、json/xml、html等。大部分人只知道html爬虫也就是通常意义上的web spider,因为它需求广泛而且解析较简单。
内容解析方式
爬虫获取的数据是多样的,Response可能是一堆字符串也有可能是一个二进制文件,这取决于文本的编码方式;Response可能是结构化的(数据库、json)也有可能是非结构化的(比如图片、视频),这取决于资源的组织形式。
解析非结构化的数据,一般需要耗费大量的资源,然后训练出一个相对拟合的、结构化的模型,最后用这个模型分析返回的数据,并且这一过程可能是不断迭代的,直到达到真正的价值转移。
这里我们只找软柿子捏。解析软柿子一般有以下几种形式:
XML/JSON/CSV
这类数据已经是非常结构化的数据了,并且有大量的第三方库支持,它们是烂柿子,这里就不捏了。
XML
JSON:
CSV:
文本
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
目的
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
正则表达式的特点是:
- 灵活性、逻辑性和功能性非常强;
- 可以迅速地用极简单的方式达到字符串的复杂控制。
- 对于刚接触的人来说,比较晦涩难懂。
python RE Module
1 | text = "He was carefully disguised but captured quickly by police." |
- 几个特殊字符要注意:
1、. 匹配任意除换行符“\n”外的字符;
2、表示匹配前一个字符0次或无限次;
3、+或后跟?表示非贪婪匹配,即尽可能少的匹配,如?重复任意次,但尽可能少重复;
4、 .? 表示匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。
1 | In [1]: s = 'aabab' |
HTML
HTML:超文本标记语言,标准通用标记语言下的一个应用。“超文本”就是指页面内可以包含图片、链接,甚至音乐、程序等非文字元素。网络爬虫主要处理的就是这种格式的文本。在python体系中,有很多自带的方法和丰富的第三方库来处理这类数据。
XPath
什么是 XPath?
- XPath 使用路径表达式在 XML 文档中进行导航
- XPath 包含一个标准函数库
- XPath 是 XSLT 中的主要元素
- XPath 是一个 W3C 标准
总之XPath 是一门在XML文档中查找信息的语言,它使用路径表达式来选取XML文档中的节点或节点集。
XML是HTML的超集合。我们也可以使用xpath语法来解析html。
路径表达式
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
示例
html.parser
htmlParser是python自带的库,可以方便的对html结构的数据做解析。
1 | from html.parser import HTMLParser |
爬虫入门
抓取网页
urllib is a package that collects several modules for working with URLs:
- urllib.request 打开和读取URLs
- urllib.error 包含urllib.request产生的错误,可以使用try进行捕捉处理
- urllib.parse 解析URLs
- urllib.robotparser 解析robots.txt文本文件
1 | # -*- coding: UTF-8 -*- |
BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间.
1 | # coding=utf-8 |
BS解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| BeautifulSoup(markup, “xml”) | BeautifulSoup(markup, “lxml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢 |
爬虫框架
Scrapy
Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
架构
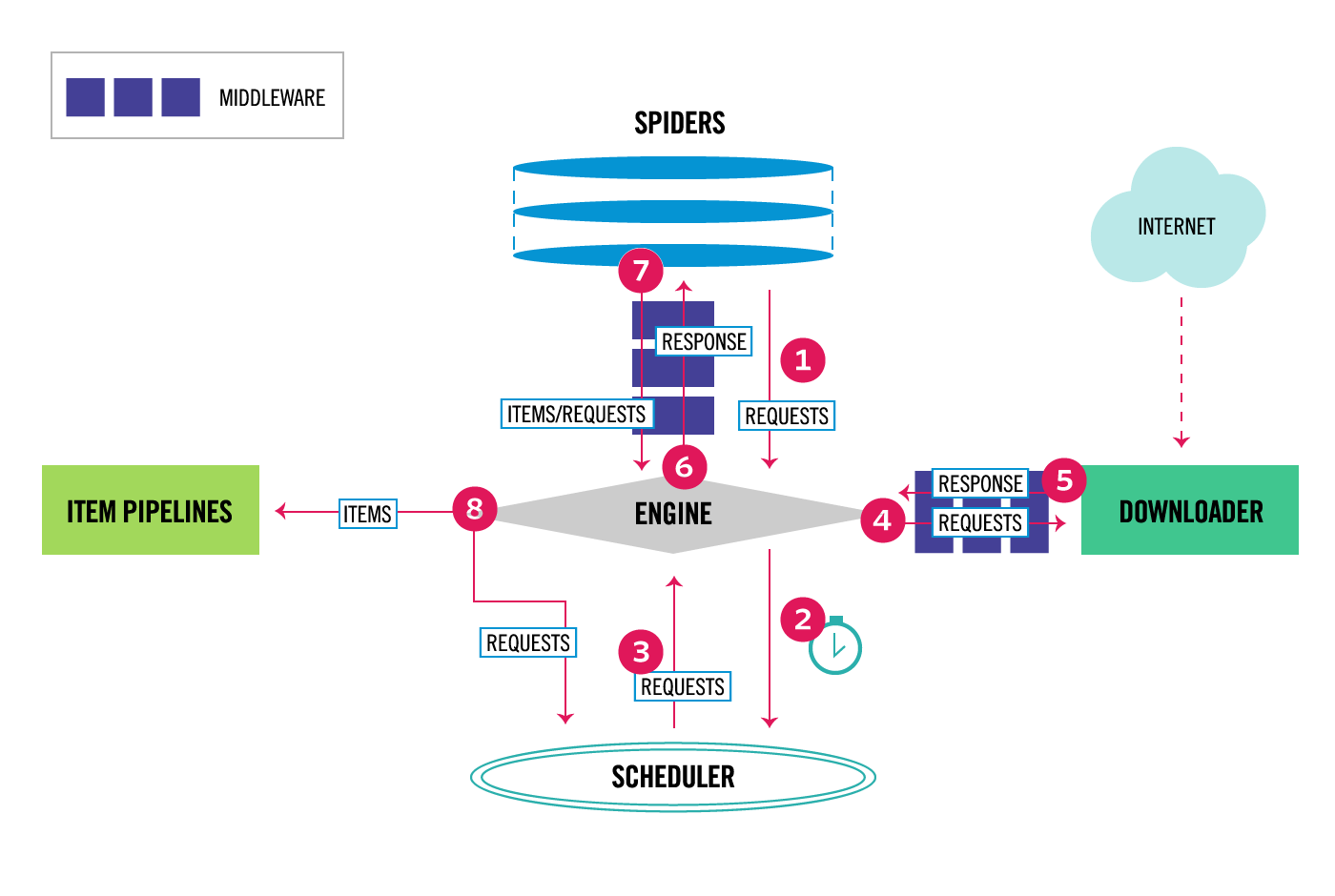
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
运行流程
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
教程
无他,官网
示例
爬取有品质的网站的数据相对简单(比如知乎、51job、豆瓣等等),它们的前端页面的元素的命名相对比较规范。大厂的页面反而好解析,而且网上有大量的实例,这里我们来爬取一些技术比较落后的网站,比如爬取宁波新楼盘数据。
步骤
- 创建工程:
scrapy startproject tutorial 创建爬虫:
1
2cd tutorial
scrapy genspider nbnewhouse cnnbfdc.com爬取数据:
scrapy crawl nbnewhouse
scrapy shell
可以在shell内分析网站,将xpath或css语句调试好。
1 | scrapy shell https://newhouse.cnnbfdc.com/projects |
code
items.py
1
2
3
4
5
6
7
8
9class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
href = scrapy.Field()
lic = scrapy.Field()
address = scrapy.Field()
developer = scrapy.Field()
type = scrapy.Field()nbnewhouse.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29# -*- coding: utf-8 -*-
import scrapy
from ..items import TutorialItem
class NbnewhouseSpider(scrapy.Spider):
name = 'nbnewhouse'
allowed_domains = ['cnnbfdc.com']
start_urls = ['http://cnnbfdc.com/']
base_url = 'https://newhouse.cnnbfdc.com/projects/'
def start_requests(self):
urls = []
page = 6
for i in range(page):
urls.append(NbnewhouseSpider.base_url + 'projects?page=%s' % i)
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
projects = response.xpath("//div[@class='group-right']")
for item in projects:
tutorialItem = TutorialItem()
tutorialItem['name'] = item.xpath("div/a/text()").extract()[0].strip()
tutorialItem['href'] = item.xpath('div/a/@href').extract()[0].strip()
tutorialItem['lic'] = item.xpath("div[2]/text()").extract()[0].strip()
tutorialItem['address'] = item.xpath("div[3]/div/div[1]/span/text()").extract()[0].strip()
tutorialItem['developer'] = item.xpath("div[3]/div/div[2]/span/text()").extract()[0].strip()
tutorialItem['type'] = item.xpath("div")[-1].xpath('text()').extract()
yield tutorialItem
Charlotte
爬虫框架
安装
数据库
安装mysql,默认用户名密码:root/root,对应配置修改Charlotte下的setting.py的DATABASES。安装库
安装python3,然后进入工程根目录,执行:1
2git clone https://github.com/LiZoRN/Charlotte.git
pip install -r requirements.txt迁移数据表
1
2python manage.py makemigrations
python manage.py migrate
爬取IP代理数据(可选)
cd 到 spiders/ProxyIp目录,命令行下执行:
scrapy crawl xici
cd 到 spiders/tools目录,清晰有效ip数据:
python proxyip.py
爬取宁波楼盘信息
cd 到 spiders/newhouse目录,命令行下执行:
scrapy crawl nbnewhouse
运行api服务
运行服务:
python manage.py runserver
api接口如下:
获取新楼盘列表:api/newhouses/?page=2&page_size=5
1 |
|
1 | 获取楼盘详情:api/newhouses/1/ |
{
“id”: 1,
“name”: “万科云鹭湾Ⅱ-6地块二期”,
“supervision_bank”: “中国建设银行股份有限公司宁波江北支行”,
“supervision_acount”: “33101983736050512431”,
“project_state”: “期房状态”,
“address”: “”,
“dev_company”: “宁波江北万科置业有限公司”,
“license_authority”: “”,
“sale_permit”: “商品房预售许可证”,
“license_key”: “2016”,
“online_saleable_area”: “24198.74”,
“online_saleable_flats”: “450.00”,
“saleable_area”: “372.24”,
“saleable_flats”: “29.00”,
“sold_area”: “23826.50”,
“sold_flats”: “421.00”,
“residential_area”: “0.00”,
“residential_flats”: “0.00”,
“sold_residential_area”: “21188.42”,
“sold_residential_flats”: “214.00”,
“reserve_area”: “0.00”,
“reserve_flats”: “0.00”,
“saleable_parking_amount”: “0.00”,
“saleable_garage_amount”: “29.00”,
“sold_avg_price”: “12234.12”,
“districts”: “江北慈城”,
“contact_phone”: “”,
“remark”: “”,
“created”: “2017-05-06T02:46:55.063256Z”
}